【科普】大模型中的Temperature和Top P原理详解
大家可能在使用AI第三方工具的时候,看到以下这两个参数:Temperature和Top P,或许看网上各种关于他们的解释可以初步知道他们和随机性有关,但是不知道其具体原理,所以小鹿在这里以通俗的语言给大家详细解释一下。
第三方模型参数图示例:
在读这篇文章之前,我假设你已经知道了大模型的基本原理是根据上下文来预测下一个词是什么。
参数相关概念
Temperature(采样温度)
Temperature,全称“采样温度”,可谓是最经典的控制模型随机性的参数了。
我们已经知道了大模型是根据上文来预测下一个单词,然而下一个单词显然有很多选择。
我们看看下面这个句子:
我是小鹿
我们假设模型在输出完“我们”之后,有以下的选择:
| 单词 | 概率 |
|---|---|
| 小鹿 | 0.7 |
| 大美女 | 0.2 |
| 女生 | 0.1 |
Temperature影响的就是这一步选择。
简而言之,Temperature如果为 0 ,那么模型就只会选择概率更高的,也就是"小鹿",也就是将随机性降到了最低。
但是当Temperature升高一些的时候,那么我们就 有一些可能性 去选择"大美女"和"女生"这个选项了,生成的内容也就多了一些灵感和创造。
这就像你考试碰到了选择题,在Temperature=0的时候你很保守,只会选确定的,但是在Temperature高的时候你化身赌狗,直接开赌。
这个可能性是基于概率的。当Temperature达到 1,甚至 2 的时候,那么选择低概率单词的概率就会大大升高,此时,模型就会表现的更为更为随机,也就是我们所说的更有创造力。通常在一些设计类的AI软件中,这个值会比普通的对话生成模型中调的大一些,具体的值会根据不同的业务场景来定义。
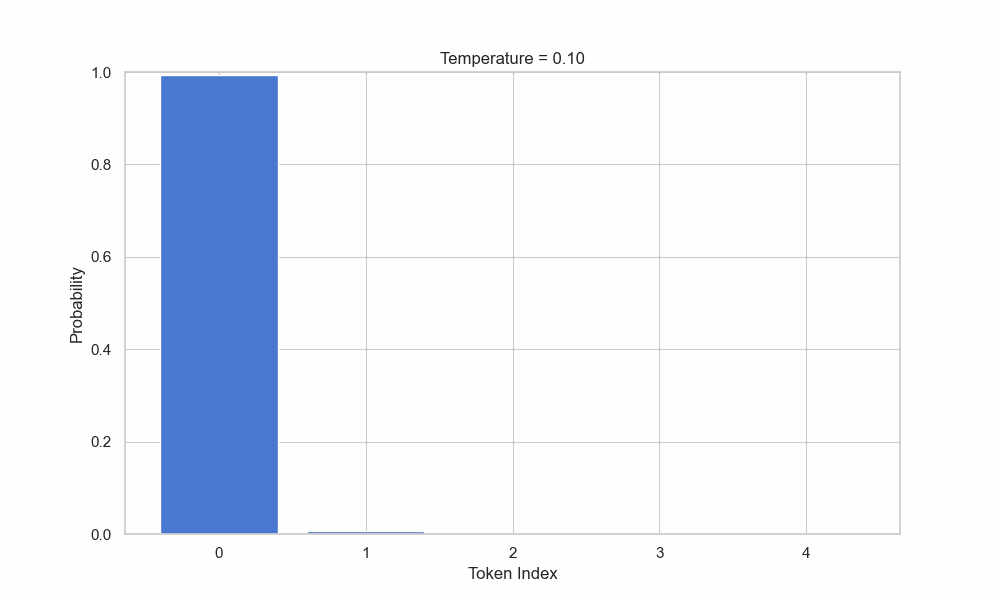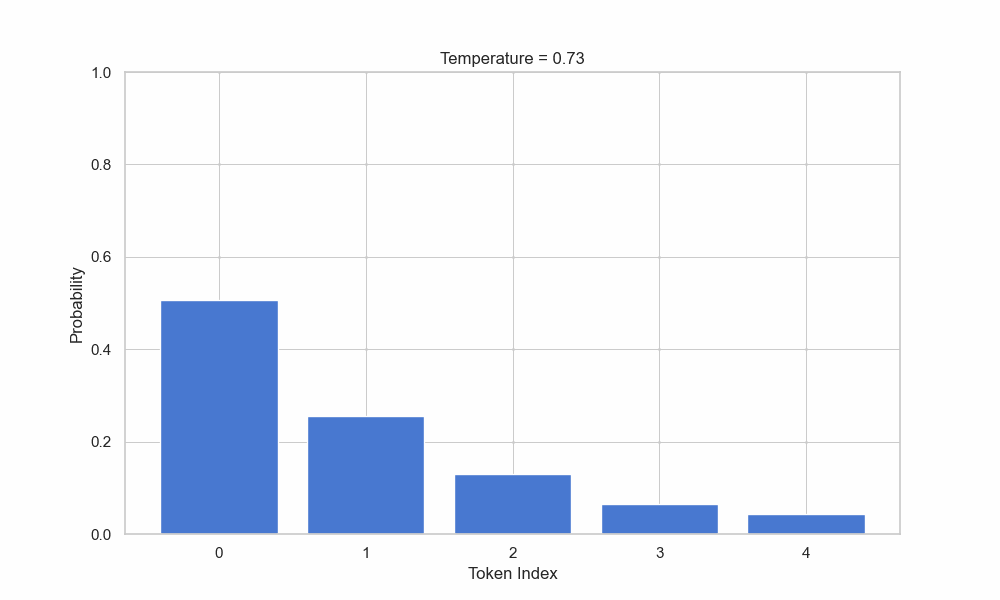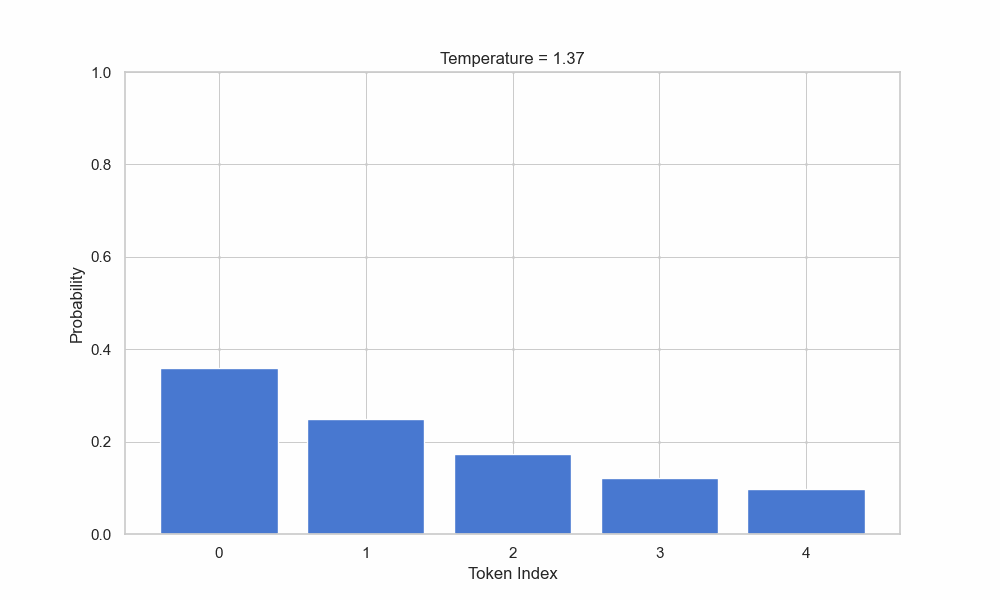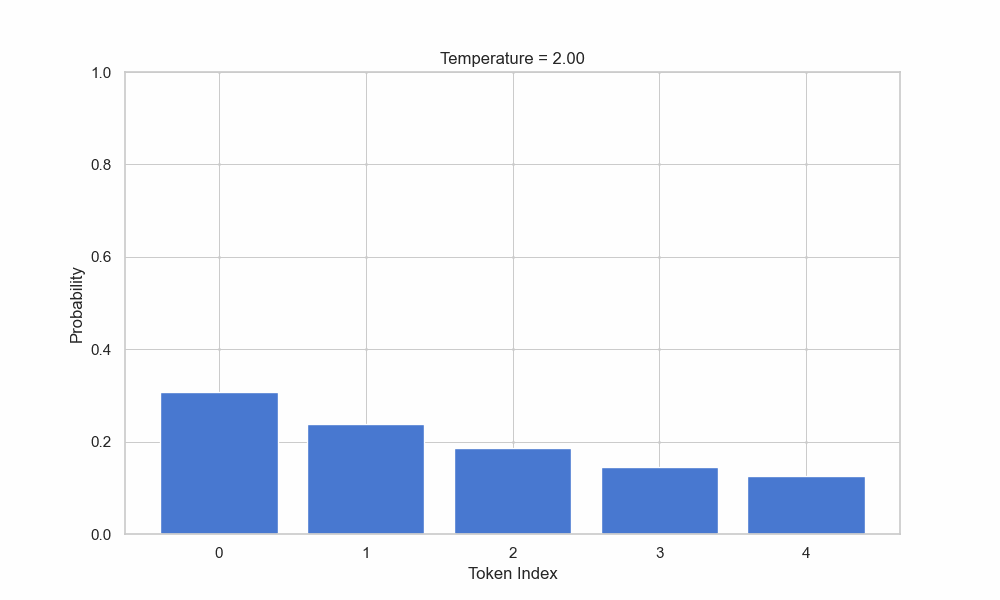
Temperature还是比较简单的,但是接下来的Top P就显得复杂了不少。
Top P(核采样)
Top P也是比较经典的一种控制随机性的东西。
如果说Temperature是控制了选择单词时候的随机性,那么Top P就控制的是选择的范围。
我们再看一下上面的句子:
我是小鹿
我们假设模型在输出完“我们”之后,有以下的选择:
| 单词 | 概率 |
|---|---|
| 小鹿 | 0.5 |
| 大美女 | 0.3 |
| 女生 | 0.15 |
| 男生 | 0.05 |
既然Top P做的是限定范围,那么它是怎么限定的呢?
原理就是在将这些概率排序之后,然后累加,直到阈值之前的全部保留。
这个阈值就是Top P。
可能还是比较抽象,我们用上面的例子来解释一下:
假设Top P为0.95,我们在选择的时候,将概率逐渐累加:
0.5<0.95,”小鹿“这个单词加入范围;
0.5+0.3=0.8<0.95,”大美女“这个单词也加入范围;
0.8+0.15=0.95,“女生”这个词加入范围之后,后面的全部忽略,再使用Temperature的方法进行选择。
想必你应该理解了原理。
但是这么做的必要是什么呢?
显然,是为了防止一些概率过低的词进入候选来干扰选项,特别是在Temperature很高的情况下。也就是在保证模型生成的内容具有高创造性的同时,还能尽可能不偏离中心,不至于出现很离谱的内容。
我写代码用AI的一个小习惯就是把Top P调到0.95,也是为了避免奇奇怪怪的bug。
同时,在出现下面这个概率很稀疏的候选的时候,Top P也能保证大部分有用的入选:
| 单词 | 概率 |
|---|---|
| A | 0.07 |
| B | 0.06 |
| … | … |
| Z | 0.01 |
想必你应该是完全理解了。
总结
这两个参数都是通过调节模型"对词汇的选择概率"来影响生成的,使用的时候应该根据使用场景来调整一下。通常来说市面上大部分大模型的api文档会告诉你,“temperature和top_p”只建议同时调整其中一个,而不是同时调整,这是为什么呢? 这是因为,调试参数 就像做对照试验,你的目的不是为了玩,而是找个比较适合自己任务的参数配置,要是两个一起调,此上彼下,就不符合控制变量法,而且再进一步就很难,因为两个参数效果不一样,搭配调试更难。调用API 时这两个参数的默认值,不同厂家是不一样的,比如 zhipu 默认是0.95,而ds,其他家一般都是 1。 小鹿个人认为,这应该只是厂家在理性 和 艺术发散之间找的平衡点
