MTranServer 是基于 Mozilla Firefox 翻译模型的自托管服务,完全通过 CPU 计算实现,无需通过独立显卡,这使得我们可以借此搭建一个「私有翻译服务」。
翻译服务作为一项历史悠久的互联网服务,早已成为互联网产品的标配。例如,Chrome 浏览器内置了 Google 翻译,微软 Edge 浏览器内置了微软翻译。国内厂商也推出了各种翻译工具。如今,在 AI 大模型的加持下,翻译质量已从「机翻」进化到接近人工翻译的水平。
然而,这些翻译服务大多依赖网络,无法离线使用。基于大模型的翻译服务响应速度也差强人意。有没有可以私有化部署甚至本地离线运行的翻译服务呢?
MTranServer 项目是一款基于 Mozilla Firefox 翻译模型的自托管服务。它虽然也基于「大模型」,但完全通过 CPU 计算实现,无需独立显卡。同时,系统资源占用率极低,仅使用英译中翻译模型时,平均内存占用仅 700MB。由于模型在本地运行,无需联网和依赖第三方服务,我们可以借此搭建一个「私有翻译服务」。
在小鹿的实际测试过程中发现,其翻译速度基本可以做到ms级别
服务器 Docker Compose 部署
MTranServer 目前支持 Docker 自部署。最新版本的 Docker 镜像支持 AMD64 和 ARM64 处理器架构,因此无论是普通的 X86-64 架构 Windows 电脑还是 Apple Silicon 架构的 Mac 都可以通过 Docker Desktop 进行本地部署。
此外,如果你希望分享这个翻译服务,也可以将 MTranServer 部署到私有云/公有云服务器上,然后通过生成的公网服务地址来分享。小鹿建议:如果要部署在公网环境,一定要配置好Token,避免被爆破或被利用。
首先给大家粘贴一下GitHub地址:
1.服务器准备一个存放配置的文件夹,打开终端执行以下命令
mkdir mtranserver
cd mtranserver
touch compose.yml
mkdir models2 用编辑器打开 compose.yml 文件,写入以下内容
修改下面的
your_token为你自己设置的一个密码,使用英文大小写和数字。自己内网可以不设置,如果是云服务器强烈建议设置一个密码,保护服务以免被扫到、攻击、滥用。如果需要更改端口,修改ports的值,比如修改为9999:8989表示将服务端口映射到本机 9999 端口。
services:
mtranserver:
image: xxnuo/mtranserver:latest
container_name: mtranserver
restart: unless-stopped
ports:
- "8989:8989"
volumes:
- ./models:/app/models
environment:
- CORE_API_TOKEN=your_token如果出现Docker镜像下载失败的情况,可以使用镜像下载(小鹿之后会单独写一篇文章来讲如何自建Docker镜像服务)
下载模型
按照官方文档,在运行前需要先将语言模型下载下来,下载地址小鹿这里就不贴出来了,大家可以直接去Github查看
还是贴一下地址吧,有部分同学可能访问Github并不顺利。模型地址
下载模型后,解压每个语言的压缩包到 models 文件夹内。
警告:如果使用多个模型,内存占用会成倍增加,请根据自己服务器配置选择合适的模型。
下载了英译中模型的当前文件夹结构示意图:
compose.yml
models/
├── enzh
│ ├── lex.50.50.enzh.s2t.bin
│ ├── model.enzh.intgemm.alphas.bin
│ └── vocab.enzh.spm启动服务
先启动测试,确保模型位置没放错、能正常启动加载模型、端口没被占用。
docker compose up正常输出示例:
[+] Running 2/2
✔ Network sample_default Created 0.1s
✔ Container mtranserver Created 0.1s
Attaching to mtranserver
mtranserver | (2025-03-03 12:49:24) [INFO ] Using maximum available worker count: 16
mtranserver | (2025-03-03 12:49:24) [INFO ] Starting Translation Service
mtranserver | (2025-03-03 12:49:24) [INFO ] Service port: 8989
mtranserver | (2025-03-03 12:49:24) [INFO ] Worker threads: 16
mtranserver | Successfully loaded model for language pair: enzh
mtranserver | (2025-03-03 12:49:24) [INFO ] Models loaded.
mtranserver | (2025-03-03 12:49:24) [INFO ] Using default max parallel translations: 32
mtranserver | (2025-03-03 12:49:24) [INFO ] Max parallel translations: 32然后按 Ctrl+C 停止服务运行,然后正式启动服务器
docker compose up -d这时候服务器就在后台运行了。
配置沉浸式翻译插件
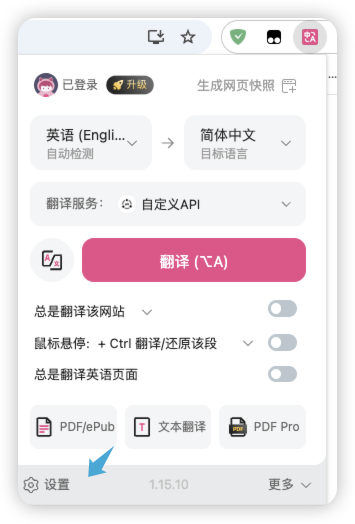
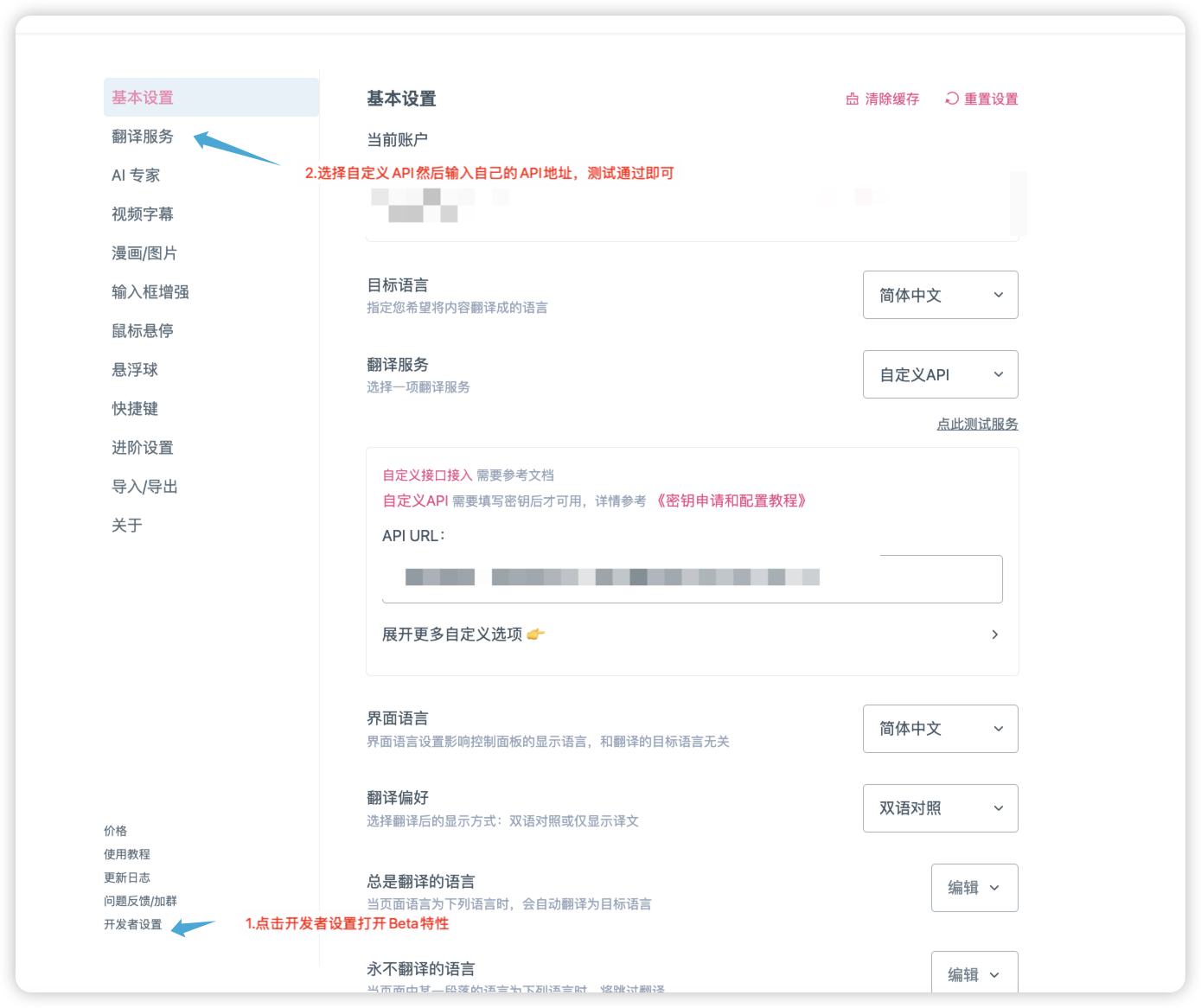
通常来说你的翻译地址为:https://test.xxxxx.com/imme?token=your_token 具体的接口和开发者调用示例可以查看GitHub文档。
